機械学習(Machine Learning、ML)は、大量の脅威データを収集および処理し、限られたリソースで新しいマルウェアを迅速かつ正確に検出し解析することが求められる現代のサイバーセキュリティにおいて重要な役割を果たすようになっています。通常、機械学習モデルの学習には大きなデータセットを用います。しかし、新しいマルウェアが大規模感染(アウトブレイク)する際、決定的に重要な初めの数時間に入手できる検体は限られています。つまり、新しいマルウェアのアウトブレイクを食い止めるためには、ごく少ない検体を元に大量の亜種を検出する必要があります。
トレンドマイクロではこの課題の解決のため、よりよい機械学習モデルの開発に取り組んでいます。2019年2月に公開したリサーチペーパー「Generative Malware Outbreak Detection」では、機械学習技術を使用したセキュリティソリューションが、大量の検体を用いた学習だけでなく、ごく少数の検体のみを用いた学習によってマルウェアの亜種を特定できることを示しました。
そして今回、トレンドマイクロは「Federation University Australia」のリサーチャと共同研究を行い、リサーチペーパー「One-Shot Malware Outbreak Detection Using Spatio-Temporal Isomorphic Dynamic Features」を公開しました。本リサーチでは、ごく少数の検体のみが利用可能な場合に「敵対的自己符号化器(Adversarial AutoEncoder、AAE)」を用いて動的にマルウェアを検出する手法を提案し、その性能を評価しました。
■同一ファミリに属するマルウェアの類似性
現代のサイバー攻撃は、しばしば複数の法人組織、産業、そして地域にまたがってマルウェアのアウトブレイクをもたらします。中でも最も悪名高い攻撃はおそらく2017年の「WannaCry」の事例でしょう。この攻撃では少なくとも世界150カ国で20万台のPCが感染したと推定されています。
攻撃者は、古いマルウェアの亜種に機能を追加するだけでなく、既存のマルウェア亜種との関連が容易に特定できないように、十分異なる新しい亜種を作成します。セキュリティリサーチャがこのように変化し続けるマルウェア亜種を解析する際、通常は少数の検体しか利用することができません。
ただし、同じマルウェアファミリを構成する亜種は、その複雑さにもかかわらず、中心的な部分の挙動は共通しています。例えば、典型的なランサムウェアは、コマンド&コントロール(C&C)サーバから暗号化鍵をダウンロードし、その後、感染PCのファイルを列挙して暗号化します。最後の手順は身代金要求文書の表示です。このような類似性はその他の種類のマルウェアにも当てはまり、同じ種類のマルウェアであれば今後も類似した挙動を示すと考えられます。この挙動の類似に注目し、少数の検体であっても変化し続けるマルウェアに対応可能な手法を提案しました。
今回のリサーチペーパーで解説した手法は、未確認の正常な検体とマルウェア亜種を区別する正確な表現を作成するために、検体のAPI呼び出しイベントから抽出した特徴の分析に敵対的生成ネットワーク(Generative Adversarial Network、GAN)を用いたものです。
あるマルウェア検体の挙動は、API識別子と当該APIに与えられた引数から成るAPI呼び出しイベントのシーケンスで構成された動的実行ログで確認することができます。この動的実行ログがディープラーニングモデルへの入力となります。図1は、あるマルウェアファミリに属する異なる亜種のAPI呼び出しイベントを視覚化したものです。
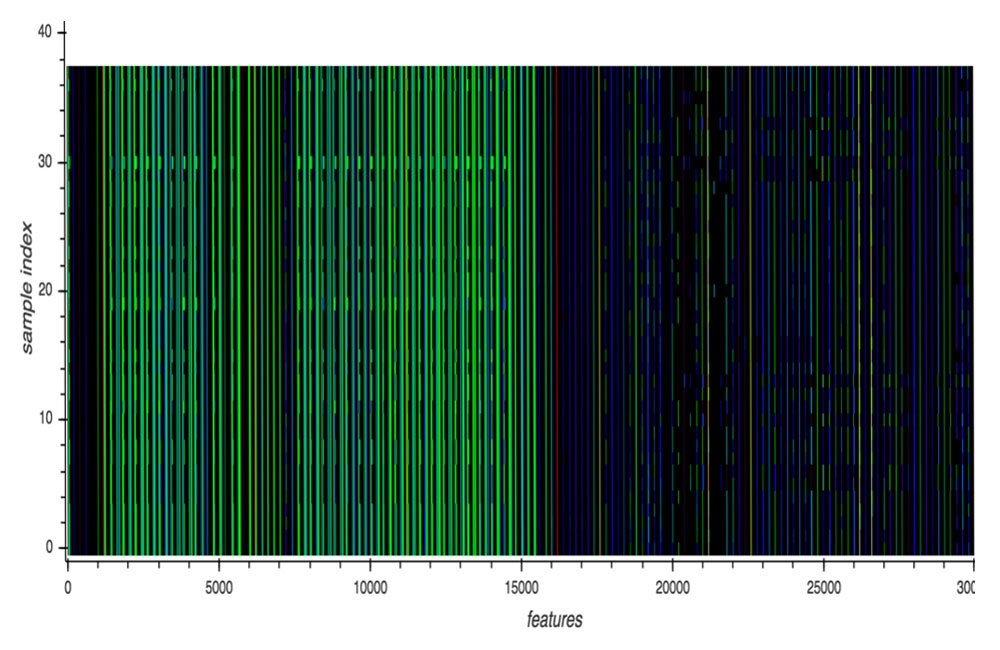
図1:あるマルウェアファミリに属する亜種のAPI呼び出しイベントを視覚化した図
図1の横軸は特徴(各検体が実行したAPI呼び出しイベントのシーケンス)、縦軸はそれぞれの亜種に割り振られた検体番号を表しています。標準化された各API呼び出しイベントは、探索テーブルを介して固有の色を割り当てたピクセルとして描画されています。それぞれの亜種には差異があるものの、API呼び出しイベントの全体的な構造は非常によく似ています。この図には38の検体が含まれており、検出名と検体数の内訳は「HO_WINPLYER.MSMIU18」が15、「OSX_Agent.PFL」が3、「OSX_Generic.PFL」が1、「OSX_SearchPage.PFM」が18、「OSX_WINPLYER.RSMSMIU18」が1です。
■その他の機械学習モデルとの比較
提案するモデルを評価するために、損失として平均二乗誤差(Mean Squared Error、MSE)を用いた敵対的自己符号化器(aae-mse)の精度を、その他の機械学習モデルを基準として比較しました。比較対象としたモデルは、「勾配ブースティング(Gradient Boosting)」、「サポート・ベクタ・マシン(Support Vector Machine)」、「ランダムフォレスト(Random Forest)」です。本リサーチには、プロプライエタリのサンドボックスシステムから収集した、実際の攻撃が確認されている2,855のMac OS Xマルウェアの検体と、7,541の正常なMac OS X用ソフトウェアの動的実行ログを用いました。この動的実行ログは、人間の専門家によって分析され、API呼び出しイベントのシーケンスの類似性に基づいてラベル付けされました。続いて、2,855のマルウェア検体によるAPI呼び出しイベントのシーケンスから353のパターンを特定し、提案するモデルの学習に使用しました。7,541の正常な検体は、提案するモデルの学習データには含めず、2つに分割して比較対象モデルの学習データおよび検証データとしました。
評価のために、API呼び出しイベントシーケンスのパターンごとに1つ、つまり353のマルウェア検体に固有なラベルを割り当ててアウトブレイクをシミュレーションしました。ゴールは、この機械学習モデルの予測がどの程度正確にラベルと一致するかを測定することです。比較対象とした他のモデルでは、小さなサンプルサイズで学習させた場合、真陽性(マルウェアをマルウェアと予測)は最大でも46%で、効果的にアウトブレイクを検出できないことが分かりました。一方、今回の提案モデルであるaae-mseは99.1%の真陽性を示しました。同時に偽陽性(正常なソフトウェアをマルウェアと予測)は0.1%にとどまりました。
提案するサイバーセキュリティのための機械学習モデルと研究結果の詳細は、リサーチペーパー「One-Shot Malware Outbreak Detection Using Spatio-Temporal Isomorphic Dynamic Features」を参照してください。このペーパーの内容は「18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering 2019 Conference and Exhibition」で発表されました。更新されたバージョンが「IEEE Xplore Digital Library」で利用可能になる予定です。
参考記事:
- 「A Machine Learning Model for Detecting Malware Outbreaks Using Only a Single Malware Sample」
by Trend Micro
翻訳: 澤山 高士(Core Technology Marketing, Trend Micro™ Research)
