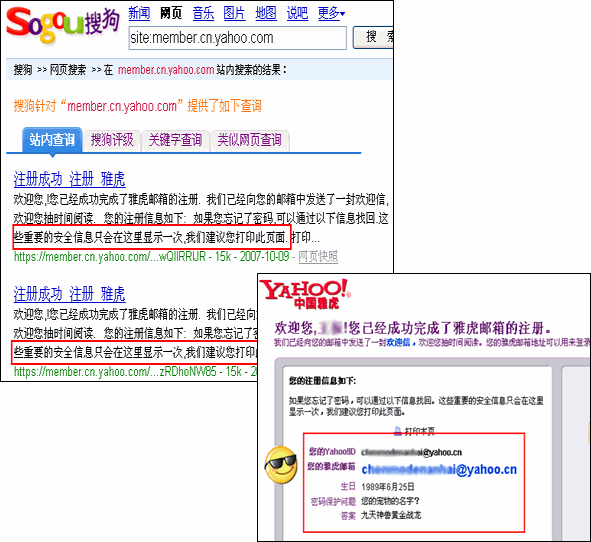
2月25日、「中国雅虎(Yahoo!)」が提供するメールサービスにおいて、個人情報の一部が不特定多数の人によりアクセスが可能な状態であったことが報じられています(参考情報1)。
今回の被害にて注目すべき点は、被害発覚に至った経緯です。
被害はインターネットのサービスとしてもはや欠かせないものと進化した「検索エンジン」により、発覚しています。
 |
|
「中国雅虎(Yahoo!)」メールサービスの個人情報漏洩発覚(出典:TechWeb) |
■検索エンジンの情報収集方法
脆弱な状態のサーバ発見に至ったカギは、検索エンジンによる情報収集方法にあります。
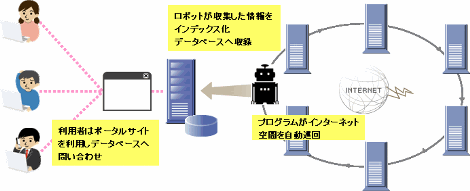
注目するのは、ロボット型と呼ばれる情報収集手法です。
 |
|
|
ロボット型検索エンジンはロボットまたは、クローラーやスパイダーと呼ばれるプログラムがインターネット上のWEBページを巡回、データを収集し、データベースに蓄積していきます。
プログラムが人の手を介すことなく収集される情報には、ノイズとも言える雑多な情報が数多く含まれています。この雑多な情報の中には時にセンシティブな情報が含まれていることがあります。
■ノイズから抽出されるセンシティブな情報
便利な道具は使う人次第で道具にも凶器にもなります。悪意あるユーザは強力な情報収集力をもつ、検索エンジンに注目しています。
読者の中にも「自分自身の名前」を検索キーワードとして、検索エンジンに入力した経験がある方がいらっしゃるのではないでしょうか。中には、検索結果として意外な情報が出力され、驚いた方もいるのではないでしょうか。
悪意あるユーザも同じ着想で、偵察活動を行います。巧みな彼らは、雑多な情報から必要な情報のみ抽出するフィルタの作成方法を知っています。彼らはWEBサイトの構造パターンを熟知した上で、予測し、検索補助コマンド(参考情報2、参考情報3)を使用することで絞り込みを行っています。
|
コマンド |
検索内容 |
|
site: |
特定のドメインのみを検索対象に指定 |
|
link: |
指定したページにリンクするページのみを検索対象に指定 |
|
cache: |
検索エンジンにキャッシュされているページを表示(Googleにて利用可能) |
|
filetype: |
ファイルの拡張子を指定し、特定の拡張子のみを検索対象として指定(Googleにて利用可能) |
|
filter:blog |
ブログやブログの記事を除いて検索結果を確認(Yahoo!にて利用可能) |
検索補助コマンドを使うことで、単純な単語よりもはるかに強力なフィルタ効果を得ることができます。「中国雅虎(Yahoo!)」の事件においても、「site:」コマンドを使用した絞り込みにより、被害発覚に至ったことが報じられています。
このように、検索エンジンのデータベースからノイズを取り除き、センシティブな情報を抽出するテクニックは、この分野の第一人者であるJohnny Long氏により、「GHDB:Google Hacking Database」として公開され、注意喚起が行われています。ここでは、公開されているカテゴリーのいくつかを紹介します。
- バナー情報から既知の脆弱性を抱えているサーバを探し出す
- エラー情報からサーバに登録されているサービスを探し出す
- ユーザ名、パスワードなどを探し出す
- ログインページを探し出す
- ファイアウォールやIDSなどセキュリティ製品のログを探し出す
- センシティブな情報を格納しているディレクトリを探し出す
- オンラインショッピングの情報(顧客データ、クレジットカード情報など)を探し出す
- ネットワーク接続されているプリンターやカメラなどのハードウェアを探しだす
これらカテゴリからも、検索エンジンからセンシティブな情報にアクセスできる可能性を推測できるのではないでしょうか。
■ウイルスへの検索エンジンハッキング実装
検索エンジンを利用した偵察行為を「検索エンジンハッキング」または「Googleハッキング」と呼んでいます。2003年頃より、その危険性が指摘され始め、年々その勢いは高まっています。
検索キーワードを工夫するだけという手軽さ、増え続ける情報に追いつくことのない管理者側の管理体制などがその要因と推測されます。
ハッキングテクニックの多くは、ウイルスに実装されることがあります。「検索エンジンハッキング」もその例外ではありません。
2004年にマスメーリング型ウイルスである「WORM_MYDOOM.M」が、自身の拡散先(メールアドレス)を探索する方法として、複数の検索エンジンを使用していることが確認されています。
公開Webサーバの調査などを実施している英国のインターネット・サービス会社ネットクラフト(Netcraft)の発表によれば、流行当時、各検索サイトの応答速度に問題を及ぼすほどの検索クエリが発行されたことが報じられています。
ウイルスは更に進化していきます。同年の12月には「WORM_SANTY.A」が確認されています。同ウイルスはサーバソフトウェアPHP Bulletin Board(phpBB)の脆弱性を突いて拡散するものでした。脆弱なバージョンを使用しているサイトを探し出すために、Googleを悪用していることを確認しています。
■グーグルが進めるハッキング対策
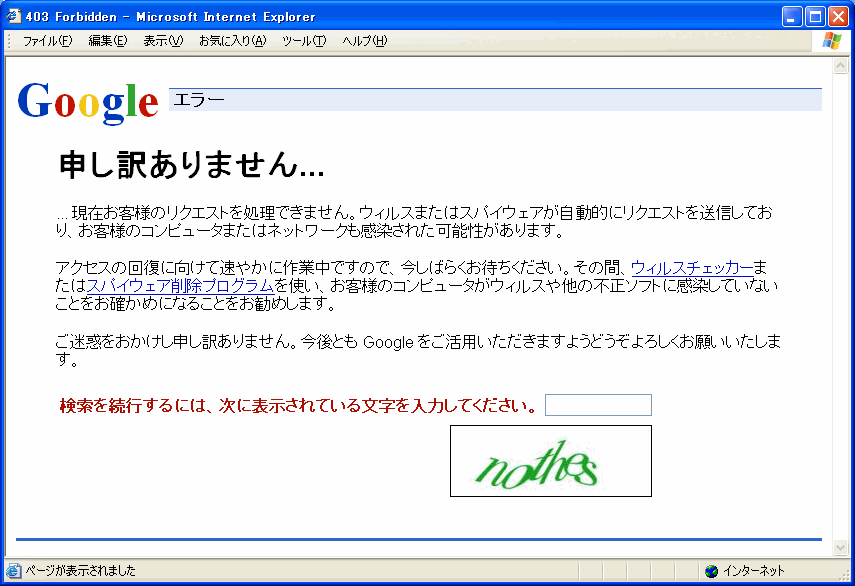
検索エンジン各社は、自社の技術が悪用されていることを好ましく感じていません。特に、ロボット型検索エンジンの雄である米グーグル社は対策に力を入れています。
グーグル社では過去報告されている検索エンジンを悪用した攻撃手法をパターン化し、一致した振る舞いが確認された場合、次のようなエラー画面を表示させ、認証要求を行うことで対策を講じています。人の手による検索であればCAPTCHA認証(画像にて表示された文字列の入力)により、エラーを回避することができます。
 |
|
|
もし、読者の方でこのような画面が表示された際には、ウイルス対策ソフトまたは、弊社の「オンラインスキャン」にて安全性の確認を行うことをお勧めします。
■WEB管理者に求められる対策
WEB管理者にとって、管理するサイトを検索結果の上位に表示させることは大きな課題であると思われます。検索エンジンハッキングに対する対策は、時に検索結果のランキングに影響を与えかねるため、慎重な対策が必要となります。
最も効果的な対策は「必要のないファイルをWEBサーバから除去する」ということです。公開期限の切れた情報をサーバから除去することなく、リンクの除去のみで済ましているケースが見られます。このような方法では、検索エンジンハッキングの手法により本来閲覧を望まない情報が特定される場合があります。公開データの取り扱いについて、適切なポリシーを策定し、遵守する必要があります。
WEBアプリケーションにおいては、適切なセキュリティ設定がなされていない場合、意図せず情報が漏洩する可能性があります。これまで、日本国内においても、懸賞サイトやアンケートサイトなどにおいて、セキュリティ設定の考慮不足により個人情報が流出した事件が数多く報告されています。
管理者に向けた対策として、3つ紹介させていただきます。
- 「robots.txt」を設置し、ロボットの巡回を拒否する
- METAタグにより、閲覧に制限をかける
- 監査ツールを利用し、検索エンジンの検索結果を確認する
「robots.txt」の設置
次のような内容を記述したテキストファイルを公開ディレクトリの最上位に配置することで、検索エンジンの自動巡回を禁止することができます。
|
User-Agent: * |
「User-Agent:」では制限したい検索エンジンを指定することができます。「*」はワイルドカードを意味し、すべての検索エンジンが対象となります。Googleのみを対象とする場合には「Googlebot」、Yahoo!のみを対象とするなら「Yahoo! Slurp」と記載する必要があります。
「Disallow:」は、制限ディレクトリを指定することができます。上記の例では「/」が指すルートディレクトリ以下のすべてのディレクトリやファイルに対するロボットの閲覧を禁止しています。
METAタグによる閲覧制限
HTMLテキスト中の<head>~</head>範囲に以下のようなタグを記載することでロボットの収集を制限することができます。
|
<head> |
「content」属性には、カンマ「,」記号を使用することにより、複数の値を設定することができます。値による効果は下記の表をご確認ください。
|
属性値 |
指定効果 |
|
noindex |
検索エンジンにインデックスさせず、検索結果に一切表示させない。 |
|
nofollow |
検索エンジンにそのリンクの価値を消失させる。 |
|
noarchive |
検索エンジンにページをキャッシュさせない。 |
|
nosnippet |
検索エンジンに要約文を表示させず、同時にキャッシュも保管させない。(Googleのみに有効) |
|
noodp |
Open Directoryプロジェクトの説明文の引用を行わない。 |
|
noydir |
Yahoo!カテゴリの説明文の引用を行わない。 |
検索エンジンの検索結果を確認
前述の「1.」、「2.」の対策は検索サービス提供者の紳士協定に基づく物です。主要な検索サービスでは、紳士協定が遵守されていますが、完全な物ではありません。
このため、対策の効果を確認する監査テストを行うことが望まれます。「site:」検索補助コマンドにて自社サイトを指定し、表示された検索結果を監査するだけでもその効果は期待できます。
より精度の高い監査を行うには、前日の「GHDB」に記載された検索クエリをカスタマイズし、実施することも有効です。
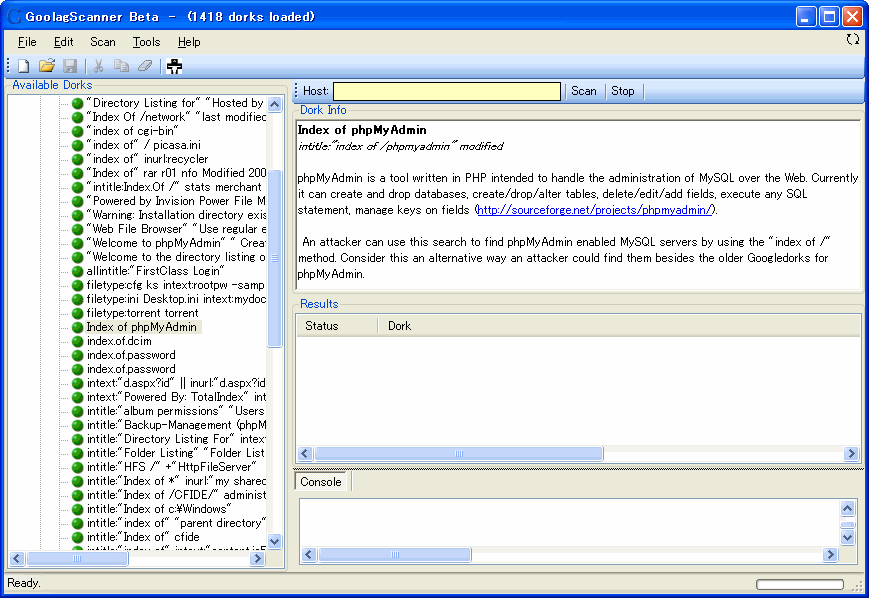
監査を支援するツールもいくつかリリースされています。先月もハッカーグループの「Cult of the Dead Cow(cDc)」が「Goolag Scan」と呼ばれる一括検索アプリケーションをリリースしています。
 |
|
|
自社に適したツールを探し出し、効率的に監査を行うことをお勧めいたします。
第2次大戦中トルーマン大統領は「アメリカの秘密情報の95%は公開情報で得られる」と述べています。現代社会でもその状況に大きな変化はありません。悪意あるユーザは、公開情報の丹念な下調べによって、攻撃の下地を作っていくことが知られています。
攻撃の布石となる情報が外部に公開されていないか、この機会に確認してみてはいかがでしょうか。
* 参考情報1. TechWeb : 「搜狗涉嫌泄露用户个人信息 雅虎邮箱受到质疑」(2008年02月25日付け)
* 参考情報2. Google Help Center : 「Advanced Operators」
* 参考情報3. Yahoo!検索ヘルプ : 「コマンド(link:, site: など)の使い方」
* 参考情報4. johnny.ihackstuff.com : 「GHDB:Google Hacking Database」
* 参考情報5. Netcraft : 「MyDoom Spread Illustrates Challenge for Phishing Defense」(2004年07月27日付け)
